Azure AI Cloud Analytics in Microsoft Fabric
14 april 2025 16 minuten

In een continu ontwikkelende digitale omgeving nemen de hoeveelheden data snel toe en groeit de complexiteit van analyses mee. Als gevolg daarvan zijn organisaties op zoek naar effectievere manieren om inzichten te verkrijgen die bijdragen aan onderbouwde besluitvorming. Om deze uitdagingen aan te pakken, spelen technologieën zoals Artificial Intelligence (AI) en Cloud Computing een steeds belangrijkere rol binnen het domein van data-analyse.
Dit artikel biedt een introductie tot Microsoft Fabric, met een focus op kernconcepten zoals workspaces, notebooks en machine learning experimenten. Ook worden de belangrijkste componenten van dit SaaS platform toegelicht, waaronder OneLake, Spark Compute, Event Streams, Data Activator en Reflexes.
Om een duidelijk overzicht te geven van hoe elk element past binnen het bredere platform, volgen we de typische dataflow binnen Microsoft Fabric: beginnend bij data-inname, gevolgd door datavoorbereiding en -analyse, en afsluitend met hoe inzichten kunnen bijdragen aan actiegerichte besluitvorming.
AI Analytics verwijst naar het gebruik van technieken en algoritmen uit de kunstmatige intelligentie om data te analyseren, informatie te interpreteren, inzichten te verkrijgen en voorspellingen of aanbevelingen te genereren. Door methoden zoals machine learning, natural language processing en datavisualisatie toe te passen, helpt AI analytics de nauwkeurigheid en efficiëntie van besluitvormingsprocessen te verbeteren. Daarnaast vermindert het de handmatige inspanning en het risico op fouten, waardoor professionals zich kunnen richten op meer strategische activiteiten.
Het verplaatsen van AI analytics workloads naar de cloud biedt extra voordelen, zoals schaalbaarheid, flexibiliteit en kostenefficiëntie. Cloudomgevingen stellen organisaties in staat om grote hoeveelheden data effectief te verwerken en snel in te spelen op veranderende behoeften. In de afgelopen jaren hebben cloudproviders speciale platforms en diensten ontwikkeld voor data analyse en business intelligence, gericht op het automatiseren van processen en het leveren van duidelijke, actiegerichte inzichten.
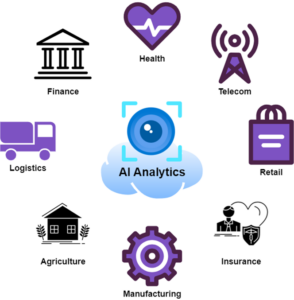
AI Cloud Analytics combineert de analytische kracht van kunstmatige intelligentie met de schaalbaarheid en flexibiliteit van cloud computing. Deze combinatie maakt geavanceerde data-analyse, verwerking en interpretatie mogelijk op een schaal die voorheen moeilijk haalbaar was. Van voorspellende modellen tot realtime besluitvorming: AI Cloud Analytics transformeert datagedreven werkwijzen in uiteenlopende sectoren.
Door deze technologieën in te zetten, kunnen organisaties nieuwe kansen identificeren, operationele efficiëntie verbeteren en innoveren binnen hun branche.
Hieronder volgen enkele praktijkvoorbeelden van hoe AI Cloud Analytics wordt toegepast in verschillende sectoren:

Microsoft Fabric is een geïntegreerd analytics platform gebouwd op Azure, ontworpen om modern databeheer te vereenvoudigen en te stroomlijnen. Het brengt verschillende functies (van data-engineering en integratie tot data science en business intelligence) samen in één omgeving. Door schaalbaarheid, AI ondersteuning en een diepe integratie met Azure te combineren, biedt Microsoft Fabric een samenhangende oplossing voor organisaties die werken met grote en complexe datasystemen.
Hoewel Microsoft Fabric sinds november 2023 algemeen beschikbaar is, krijgt het al snel erkenning als een meer geïntegreerd alternatief voor eerdere Azure oplossingen zoals Synapse Analytics, Data Factory en Power BI. Deze vereisten voorheen meer configuratie en integratie om een volledige end-to-end analytics oplossing op te zetten.
Microsoft Fabric is te beschouwen als een alles-in-één Software-as-a-Service (SaaS) platform voor data-analyse. Het ondersteunt de volledige datalevenscyclus, van opslag en transformatie tot realtime analyse en data science, via een gecentraliseerd portaal. Dit portaal brengt zowel bestaande als nieuw ontwikkelde Azure diensten samen met als doel consistentie te verbeteren en complexiteit binnen het platform te verminderen.
Deze aanpak stelt datateams in staat zich meer te richten op inzichten en resultaten, in plaats van op het beheer van onderliggende technische diensten of licentiemodellen.
De basis van Microsoft Fabric wordt gevormd door OneLake, Microsofts uniforme opslaglaag voor data. Daarbovenop zijn meerdere kernworkloads beschikbaar:
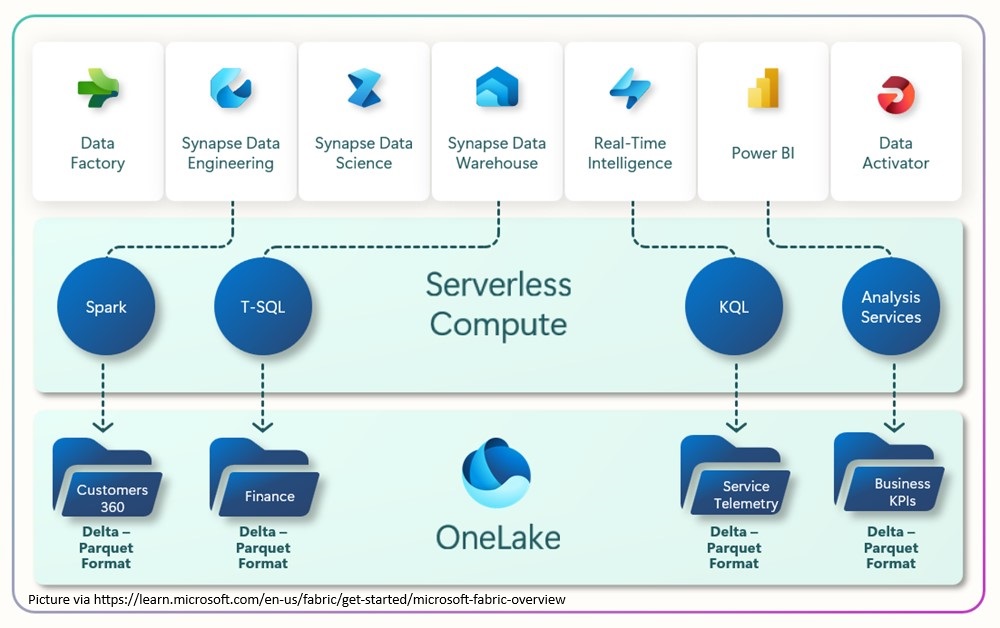
Microsoft Fabric is opgebouwd rondom OneLake, wat de centrale rol van data in de gehele levenscyclus weerspiegelt – van inname en voorbereiding tot transformatie, analyse en interpretatie. OneLake stelt organisaties in staat om data uit meerdere bronnen samen te voegen in één, uniforme omgeving.
Het doel van OneLake als gecentraliseerd toegangspunt voor alle data-opslag is het voorkomen van het ontstaan van datasilo’s. Dit is vooral relevant voor grotere organisaties, waar verschillende afdelingen of eenheden vaak geïsoleerde data opslagplaatsen onderhouden. Deze fragmentatie kan samenwerking belemmeren, leiden tot dubbele data en het potentieel voor bredere inzichten beperken die toegang vereisen tot het volledige datalandschap.
Functioneel gezien fungeert OneLake als een logische abstractielaag boven de fysieke opslagsystemen. Het ondersteunt drie hoofdtypes van opslag, die allemaal zijn gebaseerd op het Delta Parquet formaat voor het verwerken van gestructureerde data:
Microsoft Fabric introduceert het concept van workspaces, die een logische structuur bieden voor het organiseren van resources op basis van specifieke workflows, projecten of use cases. Workspaces stellen teams in staat effectief samen te werken door gecontroleerde toegang en eigendom te bieden, waardoor het makkelijker wordt om data assets en artefacten te delen tussen verschillende afdelingen of bedrijfsunits.
Naast het ondersteunen van samenwerking, helpen workspaces ook bij administratieve taken zoals kostenbeheer. Aangezien elke workspace is gekoppeld aan een specifieke capaciteit (gelinkt aan een regio), stelt het organisaties in staat om het gebruik af te stemmen op interne kostenplaatsen en de facturering nauwkeuriger te beheren.
Spark Compute is een cruciale functie binnen Microsoft Fabric, die een volledig beheerde Spark computingomgeving biedt die zowel data engineering- als data-science workflows ondersteunt, met hoge prestaties en efficiëntie.
Binnen Microsoft Fabric zijn er twee primaire manieren om Spark-code uit te voeren: via Spark job definitions en notebooks. Beide methoden hebben specifieke voordelen, en de keuze tussen deze opties hangt af van de specifieke vereisten van je taken. Hier is een kort overzicht:
Beide benaderingen kunnen samen worden gebruikt: begin met notebooks voor verkennend werk en ontwikkeling, en zet de geoptimaliseerde code vervolgens om in een Spark job definition voor implementatie in productie.
Wanneer je binnen Microsoft Fabric werkt, zijn er drie sleutelgebieden die centraal staan in het proces en aandacht vereisen, ongeacht het specifieke use case:
Data ingestion verwijst naar het proces van het verzamelen en importeren van grote hoeveelheden data in Azure voor verwerking en opslag. Deze data kan afkomstig zijn van gebruikers, maar komt vaker voort uit apparaten. Het primaire hulpmiddel in Azure voor dit doel is Azure IoT Hub, dat fungeert als centraal knooppunt voor tweerichtingscommunicatie tussen IoT-apparaten en de cloud. Het stelt organisaties in staat om realtime data van miljoenen apparaten in te laden, ondersteunt verschillende protocollen, waarborgt veilige communicatie en beheert telemetrie, commando’s en apparaatbeheer. Na binnenkomst kan de data worden doorgestuurd naar andere Azure diensten voor verdere verwerking en opslag. In dit geval wordt de data doorgestuurd naar OneLake.
Het is goed om te weten dat bij IoT apparaten een deel van de validatie lokaal op de apparaten zelf kan plaatsvinden, waardoor onnodige data inname in de cloud wordt beperkt.
Afhankelijk van het type data dat wordt ingeladen, kan de initiële opslaglocatie binnen OneLake verschillen:
Binnen Microsoft Fabric zijn er meerdere methoden beschikbaar om data in OneLake in te laden:
Notebooks stellen data scientists in staat om direct te starten met het verwerken van data en deze om te zetten van ongestructureerd naar gestructureerd formaat. Gebaseerd op de Spark-engine ondersteunen notebooks talen zoals PySpark (Python), Spark (Scala), Spark SQL en SparkR.
Dataflows bieden meer dan 300 connectors om te helpen bij het importeren en migreren van data naar verschillende onderdelen van OneLake. Deze connectors zorgen ervoor dat data beschikbaar is waar dat het meest nodig is.
Pipelines fungeren als orkestratietool waarmee workflows kunnen worden opgebouwd met control flow-logica (zoals loops en vertakkingen). Naast workflowbeheer kunnen pipelines data ophalen via de copy data activiteit en een reeks acties aansturen, zowel binnen Microsoft Fabric als in de cloud (zoals het aanroepen van Dataflows, andere Pipelines, Notebooks of Azure Functions).
Event Streams maken deel uit van de Microsoft Fabric Real-Time Intelligence omgeving. Ze maken het mogelijk om realtime event data in te laden, te transformeren en zonder code door te sturen naar verschillende bestemmingen. Meerdere bestemmingen kunnen worden ingesteld voor één enkele event stream.
Bronnen voor event data kunnen zijn:
Mogelijke bestemmingen voor event data zijn onder andere:
Voor het vastleggen van datastromen van IoT apparaten kan Event Streams de primaire methode voor data inname zijn. De Event Stream kan zo worden geconfigureerd dat data rechtstreeks wordt ingeladen vanuit IoT Hub en wordt doorgestuurd naar OneLake. Daarnaast kan het nodig zijn om meerdere Event Streams in een keten te gebruiken om data over verschillende opslaglagen heen te verplaatsen, waarbij deze wordt getransformeerd en geaggregeerd tot een eindformaat dat geschikt is voor analyse.
Zodra de verzamelde data is opgeslagen in de verschillende lagen binnen het OneLake warehouse, is de volgende stap het starten van het analyseproces. De eerste taak is het identificeren van de specifieke data die de patronen onthult die je wilt voorspellen. Dit is doorgaans de verantwoordelijkheid van een data scientist, die beschikt over sterke wiskundige en statistische vaardigheden. Het is belangrijk dat data scientists nauw samenwerken met domeinexperts die kennis hebben van de bedrijfsprocessen en specifieke context van de organisatie.
Het trainen van een machine learning (ML) model vanaf nul kan een complexe opgave zijn. Daarom is het vaak verstandig om gebruik te maken van voorgeconfigureerde modellen die zijn afgestemd op specifieke toepassingen. Azure AI Cloud Services is een suite van kant-en-klare AI API’s waarmee ontwikkelaars geavanceerde AI functionaliteit kunnen integreren in hun toepassingen zonder zelf modellen te hoeven bouwen.
Deze services bieden onder andere de volgende mogelijkheden:
Deze AI services zijn toegankelijk via HTTP API’s, met Python ncode via de SynapseML bibliotheek, of via C# met behulp van de Azure.AI namespace.
In sommige gevallen zijn generieke, voorgetrainde modellen niet toereikend en is het nodig om een aangepast model te ontwikkelen. Je hoeft echter niet helemaal vanaf nul te beginnen: vaak kun je voortbouwen op een bestaand model en dit verfijnen voor je specifieke toepassing. Voor het trainen van een ML model is schone, geldige en gelabelde historische data vereist, die de relevante kenmerken bevat waarop voorspellingen gebaseerd worden.
Er worden vaak technieken voor data-verrijking toegepast, zoals het groeperen van data over tijd om extra kenmerken te creëren, bijvoorbeeld rollende gemiddelden, statistische metingen, en tijd gebaseerde variabelen om patronen in de tijd vast te leggen.
Zodra de data gereed is, kan het trainingstraject starten. Notebooks zijn in deze fase het voorkeursmiddel, omdat ze gebruikmaken van de kracht van de Apache Spark cluster (die op de achtergrond draait), in combinatie met Python bibliotheken zoals PySpark, SynapseML en MLflow. Hiermee kun je data uit meerdere bronnen bewerken, gebruikmaken van standaardalgoritmes uit de sector, en experimenten aanmaken waarin modelversies, parameters en prestatiegegevens worden bijgehouden.
Data scientists gebruiken experimenten om verschillende trainingsruns van modellen te beheren en de bijbehorende parameters en prestatie indicatoren te analyseren. Een experiment fungeert als centrale eenheid van organisatie binnen het machine learning proces, waarin meerdere runs worden opgeslagen zodat resultaten gemakkelijk vergeleken kunnen worden. Door de uitkomsten van verschillende runs naast elkaar te leggen, kunnen data scientists bepalen welke combinatie van parameters de beste modelprestatie oplevert.
Binnen Microsoft Fabric kunnen experimenten zowel via de gebruikersinterface worden beheerd en gevisualiseerd als via Notebooks worden aangemaakt en uitgevoerd met behulp van MLflow.
Microsoft Fabric introduceert een functionaliteit genaamd Data Activator – een no-code detectiesysteem dat speciaal is ontworpen voor niet-technische analisten die zich richten op bedrijfsbehoeften en zelf relevante businessregels kunnen definiëren. Dit stelt zakelijke gebruikers zonder diepgaande technische kennis in staat om inzichten uit data te benutten en acties te automatiseren op basis van vooraf ingestelde voorwaarden.
Met Data Activator worden datasets continu gemonitord op het optreden van gedefinieerde condities. Zodra aan deze voorwaarden is voldaan, worden triggers geactiveerd die één of meerdere acties uitvoeren. Deze acties kunnen variëren van het verzenden van een bericht of e-mail, tot het uitvoeren van een aangepaste handeling op basis van de ingestelde regels.
Data Activator is bovendien geschikt voor het verwerken van streaming data. Hierdoor kan het eenvoudig worden gekoppeld aan een Event Stream als gegevensbron. Binnen Microsoft Fabric wordt de bestemming van een Data Activator aangeduid als een Reflex.
Bijvoorbeeld, een Reflex bewaakt de data van een temperatuursensor, en zodra de temperatuur een bepaalde drempel overschrijdt, wordt er automatisch een e-mailnotificatie gestuurd naar een operator. Deze kan dan tijdig ingrijpen, bijvoorbeeld door een machine te vertragen of uit te schakelen om schade te voorkomen.
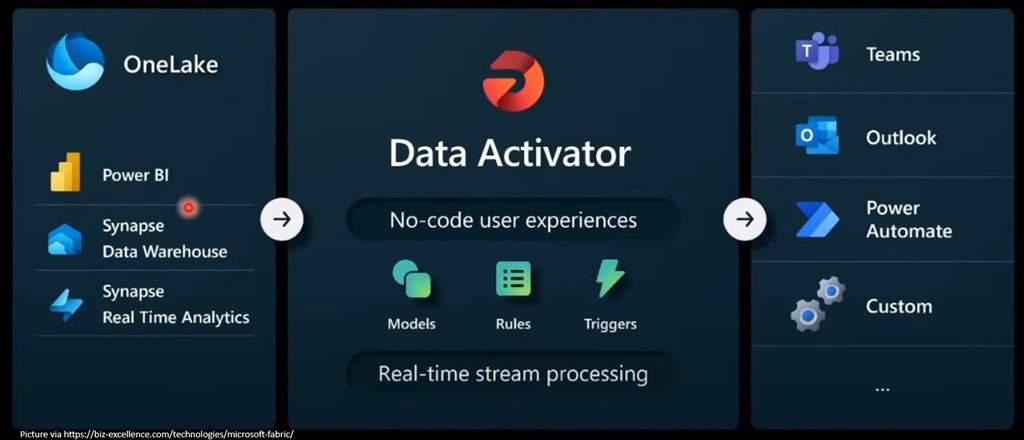
Door integratie met Power Automate vergroot Data Activator de mogelijkheden voor automatisering aanzienlijk. Er kunnen uiteenlopende acties worden uitgevoerd, zoals het uitvoeren van een HTTP aanroep om een Azure Function te triggeren, of het versturen van berichten naar een Azure Service Bus queue. Dit creëert een krachtig en flexibel platform voor het automatiseren van beslissingen en workflows, op basis van realtime data events.
De use cases en oplossingen die binnen Microsoft Fabric worden geïmplementeerd, kunnen sterk variëren afhankelijk van de sector en de specifieke behoeften van een organisatie. Om je op weg te helpen, biedt Microsoft Fabric zogenaamde Industry Solutions: vooraf geconfigureerde sjablonen die zijn afgestemd op specifieke sectoren. Deze oplossingen dienen als leidraad om de juiste resources binnen je workspace toe te wijzen en te configureren. Dit is vooral handig voor gebruikers die nieuw zijn met Fabric en niet altijd zeker weten welke tools geschikt zijn voor welke taken.
Momenteel zijn er drie Industry Solutions beschikbaar, met plannen om in de toekomst meer oplossingen uit te brengen:
Deze Industry Solutions zijn ontworpen om het opzetproces te vereenvoudigen en ervoor te zorgen dat je snel resources kunt implementeren die zijn afgestemd op de unieke behoeften van jouw sector.
Voordat je begint met het gebruik van Microsoft Fabric, is het belangrijk om de bijbehorende kosten in overweging te nemen. Net als bij elke cloudservice kunnen de prijzen toenemen wanneer je overstapt naar een volledig beheerd Software-as-a-Service (SaaS)-model. Om je een idee te geven: de kosten om te starten met een minimale “pay-as-you-go” F2 capaciteit liggen rond de $345 per maand. Dit kan worden verlaagd naar $215 per maand als je je vastlegt op een 1-jarige reservering. Voor productieomgevingen kun je verwachten dat de kosten enkele duizenden dollars zullen bedragen, afhankelijk van de schaal van je gebruik.
Naarmate we verder gaan in het tijdperk van AI en cloud computing, staat AI Cloud Analytics op het punt om aanzienlijke veranderingen teweeg te brengen voor zowel bedrijven als de samenleving. Organisaties bevinden zich op een cruciaal moment waarop ze zich moeten aanpassen aan de uitdagingen van het digitale tijdperk. De sleutel ligt in het identificeren van situaties waarin intelligente data-analyse het besluitvormingsproces kan verbeteren en mogelijk inzicht kan geven in toekomstige trends.
Of je nu kiest voor Microsoft Fabric of een andere oplossing, hangt af van je organisatie en de expertise van het team dat verantwoordelijk is voor het beheren van het systeem.
Veel van de functies die beschikbaar zijn in Microsoft Fabric, kunnen ook direct binnen Azure worden geïmplementeerd, wat meer flexibiliteit biedt maar tegen de prijs van verhoogde complexiteit. Voor teams die meer gericht zijn op bedrijfsprocessen en minder ervaring hebben met coderen of infrastructuurbeheer, is Microsoft Fabric een sterke optie. Het primaire doel van het SaaS platform van Microsoft Fabric is om de complexiteit van systeemopbouw te vereenvoudigen, zodat degenen die goed bekend zijn met hun bedrijf, grotere resultaten kunnen behalen zonder externe hulp.
Een laatste punt om te overwegen is dat veel van de functies binnen Microsoft Fabric nog in Public Preview zijn, wat betekent dat er ruimte is voor groei en verbetering. Het zou verstandig zijn om de ontwikkeling en adoptie van de oplossing te volgen, aangezien deze de belangrijkste factoren zullen zijn die Microsoft’s voortdurende investering in deze richting aandrijven.