Azure AI Cloud Analytics with Microsoft Fabric
April 14, 2025 16 minutes

In a continuously developing digital environment, data volumes are increasing rapidly, and the complexity of analysis is growing accordingly. As a result, organizations are seeking more effective ways to derive insights that support sound decision-making. To address these challenges, technologies such as Artificial Intelligence (AI) and Cloud Computing play an increasingly important role in the field of data analytics.
This article provides an introduction to Microsoft Fabric, focusing on key concepts such as workspaces, notebooks, and machine learning experiments. It also outlines the main components of this SaaS platform, including OneLake, Spark Compute, Event Streams, Data Activator, and Reflexes.
To give a clear overview of how each element fits into the broader platform, we will follow the typical data flow within Microsoft Fabric: starting with data ingestion, continuing with data preparation and analysis, and concluding with how insights can support actionable decisions.
AI Analytics refers to the use of artificial intelligence techniques and algorithms to support data analysis, interpret information, extract insights, and generate predictions or recommendations. By applying methods such as machine learning, natural language processing, and data visualization, AI analytics helps to improve the accuracy and efficiency of decision-making processes. It also reduces manual effort and the risk of errors, allowing professionals to focus on more strategic activities.
Moving AI analytics workloads to the cloud offers additional advantages, including scalability, flexibility, and cost-effectiveness. Cloud-based environments enable organizations to handle large volumes of data efficiently and adapt quickly to changing needs. In recent years, cloud service providers have developed dedicated platforms and services for data analytics and business intelligence, designed to automate processing and deliver clear, actionable insights.
AI Cloud Analytics brings together the analytical capabilities of artificial intelligence with the scalability and flexibility of cloud computing. This combination enables advanced data processing, analysis, and interpretation on a scale that was previously difficult to achieve. From predictive models to real-time decision support, AI Cloud Analytics is transforming data-driven practices across a wide range of industries.
By leveraging these technologies, organizations can identify new opportunities, improve operational efficiency, and innovate within their respective sectors.
Below are some practical examples of how AI Cloud Analytics is applied across various industries:

Microsoft Fabric is a unified analytics platform built on Azure, designed to simplify and streamline modern data management. It integrates various capabilities (ranging from data engineering and integration to data science and business intelligence) into a single environment. By combining scalability, AI support, and deep Azure integration, Microsoft Fabric provides a cohesive solution for organizations working with large and complex data systems.
Although Microsoft Fabric was made generally available in November 2023, it is already gaining attention as a more integrated alternative to earlier Azure-based solutions such as Synapse Analytics, Data Factory, and Power BI. These previously required more configuration and integration effort to create a complete end-to-end analytics solution.
Microsoft Fabric can be seen as an all-in-one Software-as-a-Service (SaaS) platform for data analytics. It supports the full data lifecycle , from storage and transformation to real-time analytics and data science, through a centralized portal. This portal brings together both existing and newly developed Azure services, aiming to improve consistency and reduce complexity across the platform.
This approach enables data professionals to focus more on insights and outcomes, rather than on managing the technical aspects of the underlying services or licensing models.
At the foundation of Microsoft Fabric is OneLake, Microsoft’s unified data storage layer. On top of this, several key workloads are available:
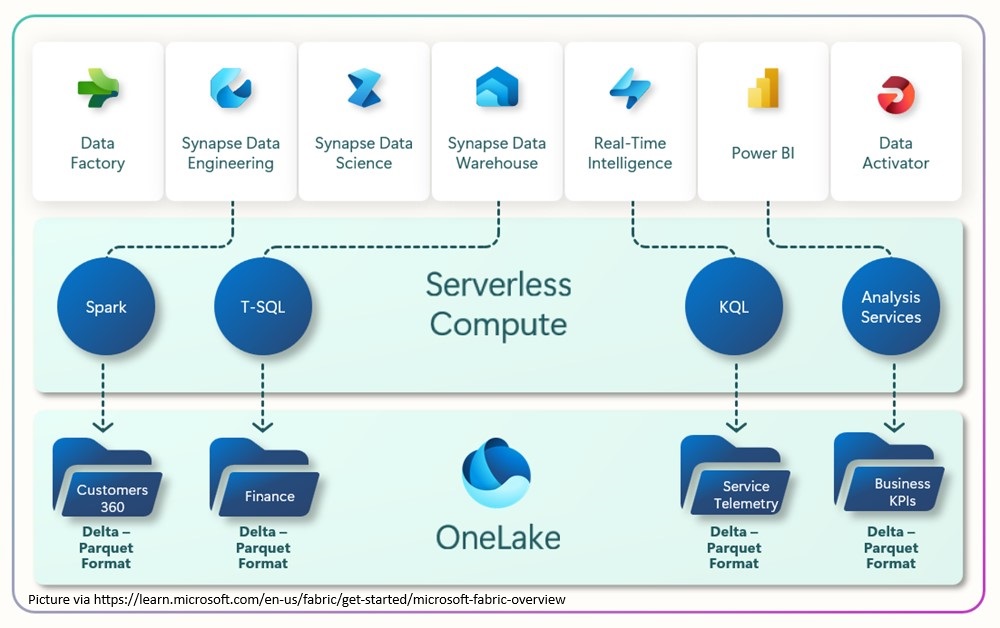
Microsoft Fabric is built around OneLake, reflecting the central role that data plays throughout the entire lifecycle – from ingestion and preparation to transformation, analysis, and interpretation. OneLake allows organizations to consolidate data from multiple sources into a single, unified environment.
The purpose of using OneLake as the centralized entry point for all data storage is to avoid the creation of data silos. This is especially relevant for larger organizations, where separate departments or units often maintain isolated data stores. Such fragmentation can hinder collaboration, lead to duplicate data, and limit the potential for broader insights that require access to the full data landscape.
Functionally, OneLake acts as a logical abstraction layer over the physical storage systems. It supports three main types of storage, all of which are based on the Delta Parquet format for handling structured data:
Microsoft Fabric includes the concept of workspaces, which provide a logical structure for organizing resources based on specific workflows, projects, or use cases. Workspaces enable teams to collaborate effectively by offering controlled access and ownership, making it easier to share data assets and artifacts across different departments or business units.
In addition to supporting collaboration, workspaces also assist with administrative tasks such as cost management. Since each workspace is associated with a specific capacity (linked to a region) it allows organizations to align usage with internal cost centers and manage billing more accurately.
Spark Compute is a critical feature within Microsoft Fabric, providing a fully managed Spark computing environment that supports both data engineering and data science workflows with high performance and efficiency.
In Microsoft Fabric, there are two primary ways to run Spark code: through Spark job definitions and notebooks. Each method has distinct advantages, and the choice between them depends on the specific requirements of your tasks. Here is a brief overview:
Both approaches can be used together: start with notebooks for exploratory work and development, then convert the finalized code into a Spark job definition for deployment in production.
When working within Microsoft Fabric, regardless of the specific use case, there are three key areas that will be central to the process and require attention:
Data ingestion refers to the process of collecting and importing large volumes of data into Azure for processing and storage. This data can originate from users, but more commonly, it is generated by devices. The primary tool in Azure for this purpose is Azure IoT Hub, which acts as a central hub for bi-directional communication between IoT devices and the cloud. It enables real-time data ingestion from millions of devices, supports various protocols, ensures secure communication, and handles telemetry, commands, and device management tasks. Once ingested, the data can be routed to other Azure services for further processing and storage. In this case, the data will be routed to OneLake.
It’s worth noting that, for IoT devices, some level of validation can be performed on-premises by the devices themselves, reducing the need to ingest unnecessary data into the cloud.
Depending on the type of data being ingested, the initial storage location within OneLake may vary:
There are multiple methods available for ingesting data into OneLake through Microsoft Fabric:
Notebooks enable data scientists to begin processing data, converting it from an unstructured to a structured format. Built on top of the Spark engine, notebooks support languages like PySpark (Python), Spark (Scala), Spark SQL, and SparkR.
Data Flows offer over 300 connectors to assist with importing and migrating data across various parts of OneLake. These connectors make it easier to ensure data is available where needed most.
Pipelines serve as an orchestration tool, enabling the creation of workflows with control flow logic (such as looping and branching). In addition to managing workflows, pipelines can fetch data through the “copy data” activity and trigger a variety of actions both within Microsoft Fabric and in the cloud (such as invoking Dataflows, running other Pipelines, Notebooks, or Azure Functions).
Event streams are part of the Microsoft Fabric Real-Time Intelligence experience. They allow you to bring in real-time event data, transform it, and route it to various destinations without writing code. Multiple destinations can be configured for the same event stream.
Event Streams can fetch event data from sources such as:
For destinations, several options are available, including:
For capturing data streams from IoT devices, Event Streams could be the primary ingestion method. The Event Stream can be configured to ingest data directly from IoT Hub and send it into OneLake. Additionally, it may be necessary to use multiple chained Event Streams to move data across storage layers while transforming and aggregating it into a final format suitable for analysis.
Once the collected data is stored across different layers within the OneLake warehouse, the next step is to begin the analysis process. The initial task is identifying the specific data that will reveal the patterns you’re aiming to predict. This is typically the responsibility of a data scientist, who brings strong mathematical and statistical expertise. It’s important that data scientists collaborate closely with industry professionals who have domain-specific knowledge of the business processes.
Training a machine learning (ML) model from scratch can be a challenging task, so a good starting point is to leverage pre-trained models that are tailored to your specific needs. Azure AI Services is a suite of ready-to-use AI APIs that enable developers to integrate advanced AI capabilities into their applications without building models from the ground up.
These services offer a variety of features, including:
These AI services can be accessed via HTTP APIs, Python code using the SynapseML library, or C# code through the Azure.AI namespace.
In some cases, generic pre-trained models are not sufficient, requiring the creation of a custom model. However, you don’t need to start from scratch. You can build upon a pretrained model and refine it for your specific needs. Training an ML model requires clean, valid, and labeled historical data, containing the relevant features that will drive the predictions.
Data enrichment techniques are commonly used, such as grouping data over time to create additional features like rolling averages, statistical measures, and time-based features to capture temporal patterns.
Once the data is ready, model training can begin. Notebooks are the preferred tool in this phase, as they leverage the power of the Apache Spark cluster (running behind the scenes) along with Python libraries like PySpark, SynapseML, and Mlflow. This enables data manipulation from multiple sources, the use of industry-standard algorithms, and the creation of experiments that log model versions, parameters, and performance metrics.
Data scientists use experiments to manage different model training runs and explore the associated parameters and metrics. An experiment serves as the core unit of organization and control for machine learning work, containing multiple runs for easy tracking and comparison. By comparing the results of different runs within an experiment, data scientists can determine which combination of parameters yields the best model performance.
Within MS Fabric, experiments can be managed and visualized through the UI, and they can also be created and executed in Notebooks using Mlflow.
Once the model is trained and achieves the desired level of performance, it can be deployed in production for real-time predictions.
In MS Fabric, models exist as standalone entities within a workspace. The simplest way to apply a model is through a Notebook, where you can connect to any data source within OneLake, instantiate the model, and apply it to the data using Python code.
The power of MS Fabric can be extended by integrating with other Azure services. For instance, compute resources running in a Kubernetes cluster can connect to OneLake and use the ML models to extract insights. As more data is collected and analyzed, the models in MS Fabric continue to learn and improve, refining predictions over time.
Microsoft Fabric introduces a feature known as Data Activator, which is a no-code detection system designed for non-technical analysts who focus on business needs and can define relevant business rules. This allows business users, without deep technical expertise, to leverage data insights and automate actions based on specific conditions.
With Data Activator, datasets are continuously monitored for predefined conditions. When these conditions are met, triggers are activated, leading to one or more actions being executed. These actions can include sending a message, an email, or even initiating a custom action based on the defined rules.
Data Activator is also designed to handle streaming data, making it easy to connect to an Event Stream as the destination. In the context of Microsoft Fabric, the destination for the Data Activator is referred to as a Reflex. For example, a Reflex could monitor data from a temperature sensor, and if the temperature exceeds a set threshold, it could trigger an email notification to an operator, alerting them to take appropriate actions, such as slowing down or shutting down a machine to prevent damage.
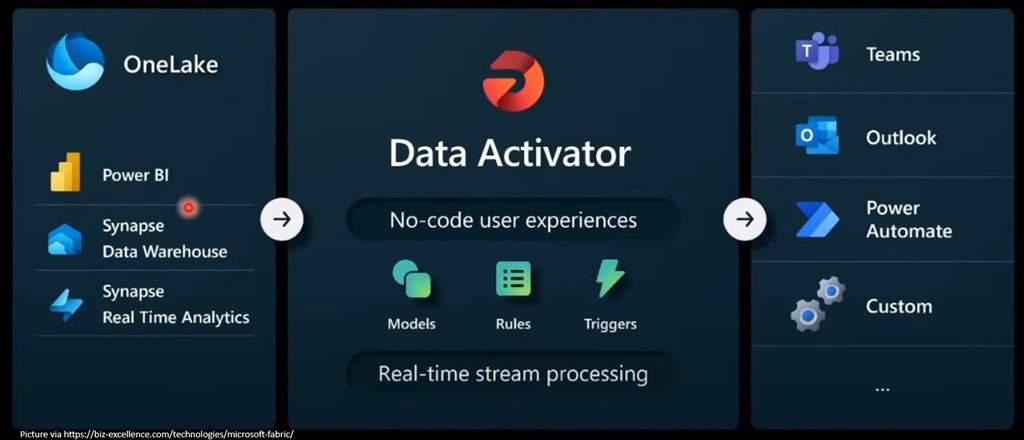
By integrating with Power Automate, Data Activator expands the possibilities for automation. Actions can be taken, such as making an HTTP call to trigger an Azure Function, or sending messages to an Azure Service Bus queue, creating a powerful and flexible environment for automating decisions and workflows in response to real-time data events.
The use cases and solutions implemented within Microsoft Fabric can vary widely depending on the industry and the specific needs of the organization. To help you get started, MS Fabric provides Industry Solutions – pre-configured templates designed for specific sectors. These solutions serve as a guide to help you allocate and configure the right resources within your workspace. This is particularly useful for those who are new to Fabric and may not always be sure of which tools to use for different tasks.
Currently, there are three Industry Solutions available, with plans for more to be released in the future:
These Industry Solutions are designed to streamline the setup process and ensure that you can quickly deploy resources tailored to the unique demands of your industry.
Before you begin using Microsoft Fabric, it’s important to consider the associated costs. As with any cloud service, the pricing can increase as you move towards a fully managed Software-as-a-Service (SaaS) model. To give you an idea, the cost to get started with a minimal “pay-as-you-go” F2 capacity is approximately $345 per month. However, this can be reduced to $215 per month if you commit to a 1-year reservation. For production environments, you can expect costs to reach several thousand dollars, depending on the scale of your usage.
As we continue to move forward in the age of Artificial Intelligence (AI) and cloud computing, AI Cloud Analytics is poised to drive significant changes for both businesses and society. Organizations are at a pivotal point where they must adapt to the challenges of the digital age. The key lies in identifying situations where intelligent data analysis can improve decision-making and potentially provide insights into future trends.
Whether you choose Microsoft Fabric or another solution depends on your organization and the expertise of the team responsible for managing the system.
Many of the features available in Microsoft Fabric can also be implemented directly within Azure, offering more flexibility but at the cost of increased complexity. For teams focused more on business processes and with less experience in coding or infrastructure management, Microsoft Fabric presents itself as a strong option. The primary goal of Microsoft Fabric’s SaaS platform is to simplify the complexity of system building, empowering those who are deeply knowledgeable about their business to achieve greater outcomes independently.
One final point to consider is that many of the features within Microsoft Fabric are still in Public Preview, meaning there is room for growth and improvement. It would be prudent to monitor its development and adoption, as these will be the key factors driving Microsoft’s continued investment in this direction.